Consistent Hashing
Problem Overview
For large applications, it is infeasible to fit the complete data set in a single server. The simplest way to accomplish this is to split the data into smaller partitions and store them in multiple servers.
There are two challenges when partitioning the data:
-
Distribute data across multiple servers evenly.
-
Minimize data movement when nodes are added or removed.
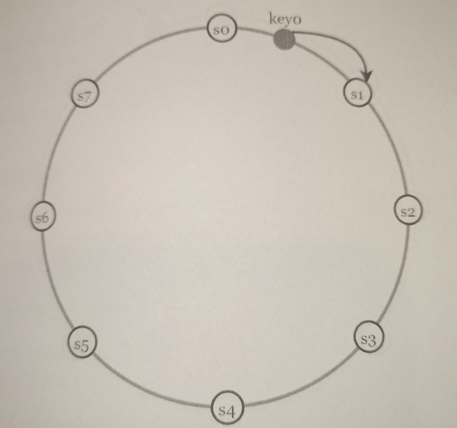
Solution: Consistent hashing
Consistent hashing is a great technique to solve these problems. This technique has the following advantages:
-
Automatic scaling: servers could be added and removed automatically depending on the load.
-
Heterogenity: the number of virtual nodes for a server is proportional in this server capacity. For example, servers with higher capacity are assigned with more virtual nodes.