Dealing with Transactions
Overview
When breaking apart our databases, maintaining referential integrity becomes problematic, latency can increase, and we can make activities like reporting more compelex.
The ability to make changes to our database in a transaction can make our system much easier to reason about, and therefore easier to develop and maintain. We rely on our database ensuring safety and consistency of our data, leaving us to worry about other things. But when we split data across database, we lose the benefit of using a database transacton to apply changes in state in an atomic fashion.
ACID Transactions
Typically, when we talk about transactions, we are talking about ACID transactions:
-
Atomicity: Ensures that all operations completed within the transaction either all complete or all fail. If any of the changes we’re trying to make fail for some reason, then the whole operation is aborted, and it’s as though no changes were ever made.
-
Consistency: When changes are made to our database, we ensure it is left in a valid, consistent state.
-
Isolation: Allows multiple transactions to operate at the same time without interfering. This is achieved by ensuring that any interim state changes made during one transaction are invisible to other transactions.
-
Durability: Makes sure that once a transaction as been completed, we are confident the data won’t get lost in the event of some system failure.
ACID but without atomicity?
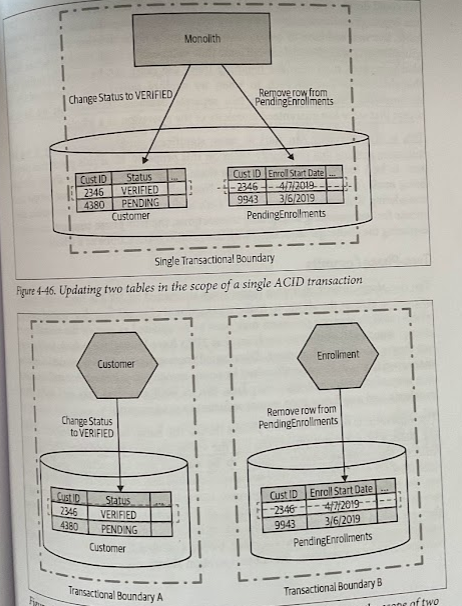
We could decide to sequence these two transactions; removing a row from the PendingEnrollments table only if we were able to change the row in the Customer table. But we’d still have to reason about what to do if the deletion from the PendingEnrollments table then failed — all logic that we’d need to implement ourselves.
Being able to reorder steps to handle these use cases can be a really useful idea. But fundamentally by decomposing this operation into two separate database transactions, we have to accept that we’ve lost guaranteed atomicity of the operation as a whole.
This lack of atomicity can start to cause significant problems especially if we are migrating systems that previously relied on this property.
Distributed Transactions & Two-Phase Commits
The 2PC algorithm is frequently used to attempt to give us the ability to make transactional changes in a distributed system.
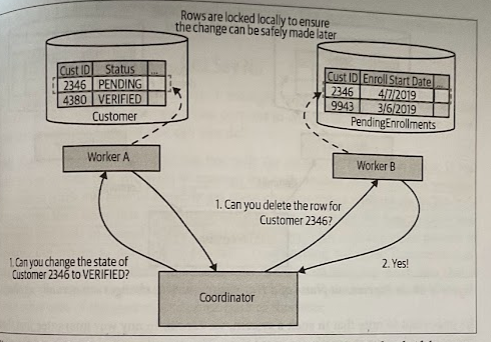
The algorithm is broken into two phases, a voting phase and a commit phase:
-
During the voting phase, a central coordinator contacts all the workers who are going to be part of the transaction, and asks for confirmation as to whether or not some state change can be made. If all workers agree that the state change they are asked for can take place, the algorithm proceeds to the next phase, otherwise the entire operation aborts. The worker is guaranteeing that it will be able to make that change at some point in the future; to guarantee that this change can be made later, Worker A will likely have to lock that record to ensure that such a change can take place.
-
If any workers didn’t vote in factor of the commit, a rollback message needs to be sent to all parties, to ensure that they can clean up locally, which allows the workers to release any locks they may be holding. If all workers agreed to make the change, we move to the commit phase. Here, the changes are actually made, and associated locks are released.
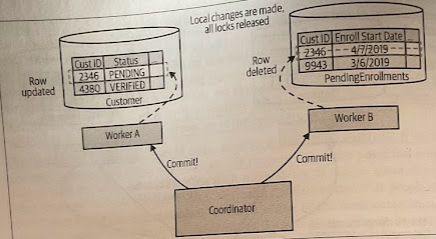
We cannot in any way guarantee that these commits will occur at exactly the same time. The coordinator needs to send the commit requests to all participants, and that message could arrive at and be processed at different times. This means it’s possible that that we could see the change made to Worker A, but not yet see the change to Worker B, if we allow for you to view the states of these workers outside the transaction coordinator.
When 2PC work, at their heart they are very often just coordinating distributed locks.
Managing locks, and avoiding deadlocks in a single-process system, isn’t fun. Now imagine the challenges of doing so among multiple participants.
The more participants you have, and the more latency you have in the system, the more issues a 2PC will have. The longer the operations takes, the longer you’ve got resources locked for!
Distributed Transactions - Just Say No!
Whenever possible, you should avoid the use of distributed transactions like the 2PC to coordinate changes in state across your microservices.
The first option could be to just not split the data apart in the first place if you want to manage this data in a truly atomic and consistent way, and you cannot work out how to sensibly get these characteristics without an ACID-style transaction; leave the functionality that manages that state in a single service.