Distribution Strategies
Distribution by Class Model
Martin Flower’s First Law of Distributed Object Design: Don’t distribute your objects!
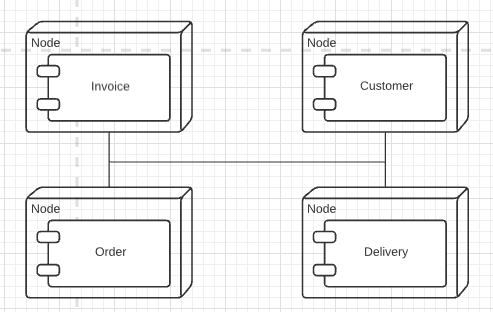
Distributing an application by putting different components on different nodes is usually not recommended.
Many tool vendors will tell you that the whole point of distributed objects is that you can take a bunch of objects and position them as you like on processing nodes. Also, their powerful middleware provides transparency. Transparency allows objects to call each other within/between a process without having to know if the calee is the same process, in another process, or on another machine.
Transparency is valuable, but while many things can be made transparent in distributed objects, performance isn’t usually one of them.
This design will usually cripple performance and/or make the system much harder to build and deploy.
“Be parsimonious with object distribution.” - Collen Roe
If you base your dsitribution strategy on classes, you’ll end up with a system that does a lot of remote calls and thus needs awkward coarse-grained interfaces. In the end, even with coarse-grained interfaces on every remotable class, you’ll still end up with too many remote calls and a system that’s awkward to modify as a bonus.
Remote and Local Interfaces
The primary reason that the distribution by class model doesn’t work has to do with a fundamental fact of computers. A procedure call within a process is very fast. A procedure call between two separate processes is orders of magnitude slower. Make that a process running on another machine and you can add another order of magnitude or more, depending on the network topography involved.
As a result, the interface for an object used remotely must be different from that for an object used locally within the same process.
A local interface is best as a fine-grained interface. A fine-grained interface is good because it follows the general OO principle of lots of little pieces that can be combined and overriden to extend the design into the future.
Thus, if I have an address class, a good interface will have separate methods for getting the city, getting the state, setting the city, setting the state, and so forth.
A fine-grained interface doesn’t work well for remote interfaces. When method calls are slow, you want to botain or update the city, state, and zip in one call rather than three. The resulting interface is coarse-grained, designed not for flexibility and extendibility but for minimizing calls.
For these reasons you can’t just take a group of classes that you design in the world of a single process, throw CORBA or some such at therm, and come up with a distributed model. Distribution design is more than that.
Clustering
In most clases the way to go is clustering. Put all the classes into a single process and then run multiple copies of that process on the various nodes. That way each process uses local calls to get the job done and thus does things faster.
You can also use fine-grained interfaces for all classes within the process and thus get better maintainability with a simpler programming model.
Where you have to distribute
You want to minimize distribution boundaries and utilize your nodes through clustering as much as possible, but there are places where you might need to separate the processes.
- Clients and servers of business software.
- Server-based application and database.
- You could run all your application software in the database process itself using stored procedures (not so practical).
- SQL is designed as a remote interface so it minimizes the cost of remote calls.
- Web system between web server and application server.
- Vendor differences / Vendor specific packages.
Distribution Boundary
You ned to limit your distribution boundaries as much as possible, but where you have them you need to take them into account. All sorts of places in the system will change shape to minimize remote calls.
You want to place coarse-grained objects at the distribution boundaries, whose sole role is to provide a remote interface to the fine-grained interface, as a facade (Remote Facade). Using this helps minimize the difficulties that the coarse-grained interface introduces. This way only the objects that really need a remote service get the coarse-grained methods, and it’s obvious to the developers that they’re paying that cost. By keeping the coarse-grained interfaces as mere facades, however, you allow the people to use the fine-grained objects whenever they know they are running in the same process, making the distribution policy more explicit.
Hand in hand with Remote Facade is Data Transfer Object. You also need to transfer coarse-grained objects. You usually can’t send the domain object itself, because it’s tied in a Web of fine-grained local inter-object references. So you take all the data that the client needs and bundle it in a particular object for the transfer.
Many people in the enterprise Java community use the term value object for Data Transfer Obejct, but this clash with the term Value Object as design pattern.
The Data Transfer Object appears on both sides of the wire, so it’s important that it not reference anything that isn’t shared over the wire. This boils down to the fact that a Data Transfer Object usually only references other Data Transfer Objects and fundamental objects such as strings.
Another route to distribution is to have a broker that migrates objects between processes. The idea here is to use a Lazy Load scheme where, instead of lazy reading from a database, you move objects across the wire. The hard part of this is ensuring that you don’t end up with lots of remote calls.
Interfaces for Synchronous Distribution
Traditionally the interfaces for distributed components have been based on remote procedure calls, either with global procedures or as methods on objects.
In the last couple of years, we’ve begun to see interfaces based on XML over HTTP, SOAP is probably going to be the most common form of this interface.
XML-based HTTP communication is handy for several reasons. It easily allows a lot of data to be set, in structured form, in a single roundtrip. The fact that XML is a common format with parsers available in many platforms allows systems built in overy different platforms to communicates.
Even so, an object-oriented interface of classes and methods have value too. Moving all the tranfered data into XML structures and strings can add a considerable burden to the remote call. If both sides of the wire use the same binary mechanism, an XML interface doesn’t provide much benefit. If you have two systems built with the same platform, then you’re better off using the remote call mechanism built into that platform.
Web services become handly when you want different platforms to talk to each other.
Of course, you can have the best of both worlds by layering an HTTP interface over an object-oriented interface. All calls to the Web server are translated by it into calls on an underlying object-oriented interface. But it does add complexity since you’ll need both the Web server and the machinerty for a remote OO interface. Therefore, you should only do this if you need an HTTP as well as a remote OO API or if the facilities of the remote OO API for security and transaction handling make it easier to deal with these issues than using non-remote objects.
“My preference is for a message-based approach that’s inherently asynchronous. Digging into patterns for message-based work is asizable topic on its own.” - Martin Fowler