Breadth-first Search
Overview
Breadth-first search is one of the simplest algorithms for searching a graph and the archetype for many important graph algorithms.
Prim’s minimum-spanning-tree algorithm and Dijkstra’s single-source shortest-paths algorithm use ideas similar to those in BFS.
It’s also called level order traversal : The search radiates out from the starting point. You’ll check first-degree connections before second-degree connections.
Extra memory, usually a queue, is needed to keep track of the child nodes that were encountered but not yet explored.
Notice that this only works if you search items in the same order which they’re added to the list. This is why queues are commmonly used. Otherwise, you might end up checking a second-degree connection before you finished with all first-degree connection.
Use cases
There are two general problems that BFS can solve:
- Find if there’s a path from node A to node B.
- Find the shortest distance between two things.
- Calculate the fewest moves to victory in checkers.
- Spell checker (fewest edits from your misspelling).
- Find the doctor closest to you in your network.
Moreover, BFS can be used to solve many problems in graph theory, for example:
- Cheney’s algorithm (Tracing garbage collection)
- Find the shortest path between two nodes.
- Serialization/deserialization of a binary tree vs serialization in sorted order, allows the tree to be re-constructed in an efficient manner.
- Testing if a graph is bi-partite.
- Parallel algorithms for computing a graph’s transitive closure.
Implementation
Tree: iterative implementation
procedure BFS(T, root)
let Q be queue
label root as visited
Q.enqueue(root)
while Q is not empty
v = Q.dequeue()
// Some logic with v here
if v is the end
return v
for all edges from v to w in T.adjacentEdges(v) do
// For a binary tree, those are the left and right children
if edge is not visited
label edge as visited
Q.enqueue(edge)
BFS starts at the tree root and explores all nodes at the present depth prior to moving on to the nodes at the next depth level.
The search tree is broadened as much as possible before going to the next depth.
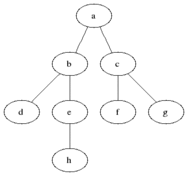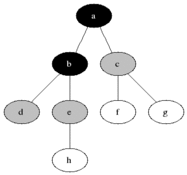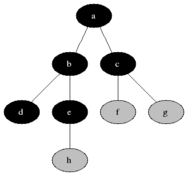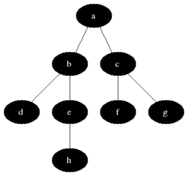
Level order: F, B, G, A, D, I, C, E, H.
- It uses a queue (FIFO).
- It checks whether a vertex has been explored before enqueing it.
If $G$ is a tree, replacing the queue with a stack will yield a DFS algorithm.
Graph: Coloring
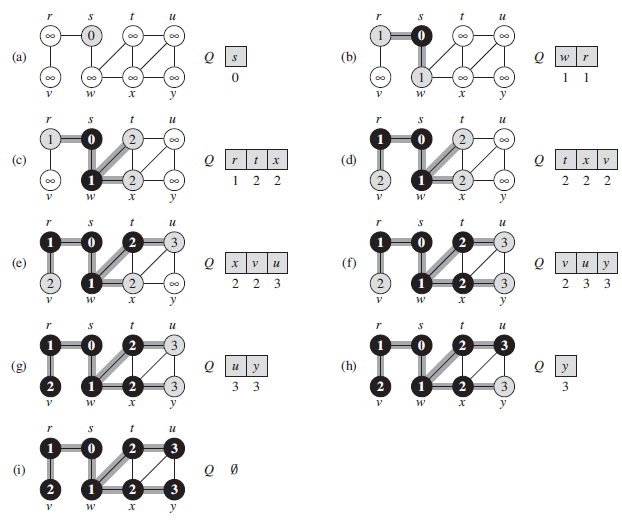
The fllowing BFS implementation assumes that the input graph $G = (V, E)$ is represented using adjacency lists.
BFS(G, s):
for each vertex u in G.V - { s }
u.color = WHITE
u.distance = +infinity
u.predecesor = NIL
s.color = GRAY
s.distance = 0
s.predecessor = NIL
Q = empty_set
ENQUEUE(Q, s)
while (Q != empty_set)
u = DEQUEUE(Q)
for each v in G.Adj[u]
if v.color == WHITE
v.color = GRAY
v.distance = u.d + 1
v.predecessor = u
ENQUEUE(Q, v)
u.color = BLACK
u.distanceholds the distance from the sourcesto vertexucomputed by the algorithm.
Complexity
-
Time complexity: The time complexity can be expressed as $O( V + E )$, since every vertex $V$ and every edge $E$ will be explored in the worst case. -
Space complexity: When additional data structures are used to determine which vertices have already been added to the queue, the space complexity can be expressed as $O( V )$.
Note that $O( E )$ may vary between $O(1)$ and $O( V ^2)$, depending on how sparse the input graph is.
Analysis
We use aggregate analysis.
- Enqueuing and dequeuing take O(1) time, and so the total time devoted to queue operations is O(V).
- The procedure scans the adjacency list of each vertex only when the vertex is dequeued, it scans each adjacency list at most once. Since the sum of the lengths of all adjacency lists is $\Theta(E)$, the total time spent in scanning adjacency lists is O(E).
Thus, the running time of BFS procedure is O(V + E). Thus, BFS runs in time linear in the size of the adjacency-list representation of G.
Complexity in trees
Refer to this SO post.
| In case the graph is a tree, then the number of edges is $ | V | - 1$. Therefore, the time complexity is $O( | V | )$ because $O( | V | + | E | ) = O( | V | + | V | - 1)$. |
Examples
Maze-solving
It is used in the Maze-solving algorithm.

Chess endgame
In a chess endgame, a chess engine may build the game tree from the current position by applying all possible moves, and use BFS to find a win position for white.
In contrast, (plain) DFS explores the node branch as far as possible before backtracking and expanding other nodes, may get lost in an infinite branch and never make it to the solution node.
On the other hand, DFS algorithms get along without extra memory.